一. 缓冲区溢出入门
过去缓冲区溢出的覆盖方法有两种:
- NNNNSSSSRRRR - 【Nop Shellcode RetAddr】适用于大缓冲区,返回地址不能准确定位
- RRRRNNNNSSSS - 【RetAddr Nop Shellcode】“R”往后跳到Nop中顺序执行,但在windows下“R”(指向栈空间)中必定包含0,即溢出易截断
tips:
linux-32bit 4G内存:
User Space: 0x08048000~0xbfffffff (低3G)
Kernel Space: 0xc0000000~0xffffffff (高4G)
栈(属于User Space)是从0xc0000000开始往低地址扩展的
linux-64bit 虚拟地址空间是2^48=256TB (可通过/proc/cpuinfo来查看多少位物理地址、多少位虚拟地址)
User Space: 0x0 ~ 0x00007fff ffffffff
Kernel Space: 0xffff8000 00000000 ~ 0xffffffff ffffffff
栈也是从User Space最高地址开始往低地址扩展的
【参考:http://tencentdba.com/blog/linux-virtual-memory-glibc/】
windows 栈内存大小默认为1M,32bit:0x00xxxxxx 64bit:0x00000000 00xxxxxx (ps:这个数据是我从debugger中查看总结的,并非官方结论)
由于上面的溢出方法都存在局限性,目前主要使用如下两种方法:
- AAAARRRRSSSS - 【A=任意值 R=jmp esp的地址 S=Shellcode】 将返回地址覆盖为jmp esp指令的地址,当返回地址被弹出执行后esp也+4,即执行shellcode位置,因此jmp esp便会去执行shellcode
- 【AAAA - jmp 04 - jmp ebx的地址 - Shellcode】通过将返回地址覆盖为一个异常的值,从而触发windows的异常处理机制,即去异常处理链中依次寻找对应异常的处理程序,而此时ebx会指向当前地址的前4个字节(即ebx=当前next指针所在地址)。因此通过覆盖异常处理程序的地址为jmp ebx的地址,从而去执行ebx所指向的指令;而ebx指向的位置已被我们覆盖为【nop nop jmp 04】,因此便会执行jmp 04指令,而该指令的效果是跳转至该指令的下一条指令+4(+4正好跳过jmp ebx的地址对应的4个字节)的位置处去执行,即我们覆盖的shellcode;因此通过这样构造便执行了shellcode
二. shellcode编写
分为3步进行:
- 写成C的源码形式(考虑好要调用哪些API,如MessageBox()等)
- 将源码写成汇编指令形式,以__asm{ }结构封装在源码中 (涉及如何获取API的地址(LoadLibrary+GetProcAddress),参数如何压栈,以及参数地址的压栈)
- 在VC6.0中按F10进入调试,打开反汇编窗口,然后将源码中__asm{}里的汇编指令对应的机器码copy出来即为shellcode
tips:
当要获取LoadLibrary API的地址时,不能传入"LoadLibrary"这个字符串作为参数,因为kernel32.dll库中不存在LoadLibrary这个函数,只有LoadLibraryA(ascii参数)和LoadLibraryW(unicode参数);
对于直接在源码中调用LoadLibrary()函数的情况,其实在汇编代码中它会被编译成LoadLibraryA();
进一步来说LoadLibraryA()其实只是一层封装,在其中系统会自动把ASCII参数变成Unicode参数,然后调用LoadLibraryW()函数。
三. 后门的编写
shellcode的功能有很多,常见的一些是:
开一个本地端口、反连攻击机、下载文件并执行、传输一个文件并执行
更高级的功能有:
直接监听、直接重用端口、恢复堆链表、直接找出已有的socket来使用
1. 开本地端口,接收并执行攻击机传来的命令(正向连接)
主要思路:目标机作为服务器端,开一个本地端口并监听;攻击机作为客户端,正向连接目标机的端口;一旦建立连接后,攻击机向目标机发送命令,目标机接收并执行该命令,同时将执行结果返回给攻击机。

缺点:若目标机开启了防火墙,这种方法就不行了,因为目标机的防火墙会阻断对非法端口的连接,这时便需要反向连接(见2)
2. 反连攻击机,接收并执行攻击机传来的命令(反向连接)(P159)
主要思路:攻击机作为服务器端,监听一个端口;目标机上运行的shellcode是作为客户端,来主动连接攻击机监听的端口;一旦建立连接后,其余的通信及执行命令便与正向连接一致。

优点:一般的防火墙不会阻断由内往外的连接,所以很多情况下可以成功
正向和反向都是用于建立网络连接的,那么一旦连接建立好之后,如何在目标机上执行攻击机传输过去的命令呢?这时便需要管道机制。
a) 管道是用于进程间通信的,是一块共享内存,用于一个进程往管道一端中写,另一个进程从管道另一端读。在这里,即用于目标机上运行的shellcode父进程和执行命令的cmd.exe子进程之间的通信。因此整个流程为:
攻击机给目标机发送命令 ——> 目标机中shellcode父进程将命令通过管道1传输给cmd子进程 ——> cmd进程执行命令
目标机将执行结果发送给攻击机 <—— cmd子进程将执行结果通过管道2中传输给shellcode父进程 <—— cmd进程执行结束但不退出
用图表示为:
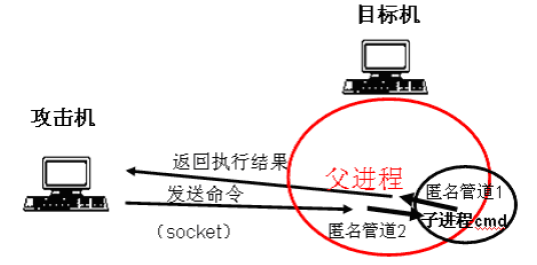
为什么上面会需要2个管道呢?因为cmd子进程需要从管道中读命令,并将执行结果写回管道;如果只用1个管道,那么一旦cmd子进程将返回信息写回管道了,便会被它自己给读取到,而不是由shellcode父进程来读了。进一步总结,这里用的匿名管道的读写端都只能被1个进程所占有,上面若只用1个管道的话,它的读端和写端都会被shellcode父进程和cmd子进程同时占有,这样就没法按需求通信了,因此需要2个管道。
上面这种方式即为使用两个管道来实现shellcode父进程和cmd子进程之间的通信,称之为“双管道后门” (P126)
优点:只需创建1次cmd进程
缺点:cmd进程一旦创建好便会一直运行着,容易被发现
b) 还有一种方式只使用一个管道即可,称为“单管道后门” (P131)
攻击机给目标机发送命令 ——> 目标机中shellcode父进程将命令作为参数去创建cmd子进程 ——> cmd进程执行命令
目标机将执行结果发送给攻击机 <—— cmd子进程将执行结果通过管道传输给shellcode父进程 <—— cmd进程执行结束并退出
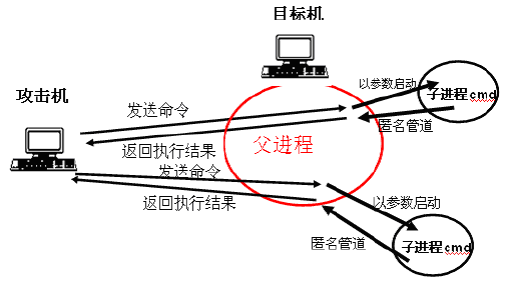
这里为什么只用1个管道就好了?因为cmd子进程只会对这个管道进行写,而shellcode父进程只会从管道中读取执行返回信息。
那么shellcode父进程是如何将命令传给cmd子进程的呢?是通过创建cmd子进程时,即将要执行的命令作为参数传递给CreateProcess()了,因此cmd子进程一执行即实现了攻击者想要执行的命令。进一步在这种情况下,cmd子进程执行完了需要能够立即退出,因为此时它已不能再去读取命令,不退出的话只会作为无意义进程存在,且不断累积的话容易被发现,所以创建cmd子进程时以"cmd.exe /c user_cmd"参数来创建,其中/c选项表示命令执行完毕后退出DOS窗口程序。
优点:来一个命令数据即就马上开一个cmd进程执行并退出,所以在目标机上不会有cmd进程一直运行着,不易被发现
缺点:每执行一条命令就要创建一个cmd进程,开销相对较大
c) 还有一种不用新建管道的后门——“零管道后门“ (P157)
可以直接利用网络通信时的Socket句柄来替代cmd进程的输入和输出句柄,即在调用CreateProcess(...si...)时对参数si(STARTUPINFO)进行一些设置,这样cmd进程的输入输出就可以直接和远程通信了,省去了进程间传输:
si.hStdInput = si.hStdOutput = si.hStdError = (void*)Socket
需注意的是,要使得直接使用Socket句柄来作为cmd进程的通信句柄,那么创建Socket句柄时也需要有些特殊处理,即要用WSASocket() API来创建Socket,而不是一般的socket() API,因为WSASocket()创建的Socket默认是非重叠套接字,这样可以把才可以将cmd的输入输出转向该套接字,而socket()创建的Socket是重叠套接字,无法实现这一功能。